Introduction
I am developing an application for the game Path of Exile, that will predict item prices based on the item quantity and the item price history throughout the season. It is a straightforward implementation that updates the prices for items at a fixed frequency, and requires items and their categories to be pre-populated in the database.
I am running my MongoDB server on the Atlas Free Tier, hosted on AWS.
The core flow is as follows: there are several categories for whom we already have general information prepared, we first create ItemCategory documents with this information for each category. Then we fetch data for all items belonging to that category. The poe.ninja website caches its API responses and we’re able to quickly fetch the desired data even with relatively large responses. We initially made all these API calls in a loop, and the whole process was quite smooth as the response time is always quick. Upon getting the data and parsing each entity in the response array into Pydantic models, we then map the data in the form <category_name: item_data> where item_data is the list of items we fetched from the API. Do keep in mind that this flow will change as optimize the script down the line.
Pydantic & Its Usage Here
We create either CurrencyItemEntity or ItemEntity Pydantic model instances for each entity in API responses, based on whether it belongs to Currency or the other Item type, as items in the Currency category have a separate API response schema. Pydantic helps maintain data integrity and validates the response data, making it easier to deal with potentially unstructured third-party data (although the APIs in this case are very consistent). There would definitely be an additional overhead for parsing the item data into a Pydantic model instance for each entity, but being able to enforce schema for third-party data in this case, and getting consistent type hint support is well worth it. Its performance has also been vastly improved with the version 2.0 release that happened late last year.
The Naive Approach: Single Insertions
The code for the naive approach and the first iteration of the script is available here. Here we are iterating over all categories, getting their response data and mapping them into the hashmap with category name as key, and the data array as value. It does not take much time to gather data for 31,000+ items, as mentioned above due to the quick API responses.
Calling save_item_data, It takes us an average of 1216 seconds or 20 minutes 16 seconds to parse each entity’s data, create and insert Item document instances and save them to the database one-by-one. I think this time is acceptable since the script meant to be run rarely, however it is practically very slow and not convenient. This makes extending the script or re-running it a chore. I am also interested in knowing how much time we can shave off from this, especially since there is a very simple optimization available. Memory usage for this approach would be high too, since we’re loading all item data entities in memory and have two objects for each entity. We will look into memory management after improving the execution time.
Each save call requires network round trips between the app and the database, and database processing time. These accumulate rapidly as we save a large number of documents one-by-one.
The Good Approach: Bulk Insertions
The modified script using approach is available here. I found using insertMany for bulk-inserts the most common and the most impactful approach, when I looked for improvement advice. Pushing all DB instances to an array and bulk-inserting them all at once, took us just ~10.7 seconds! This is an incredible improvement and should be the first choice if you need to insert multiple documents.
The problem here is the memory usage, which peaks at roughly 350MB and only drops towards the end of the script, where we see memory being released.
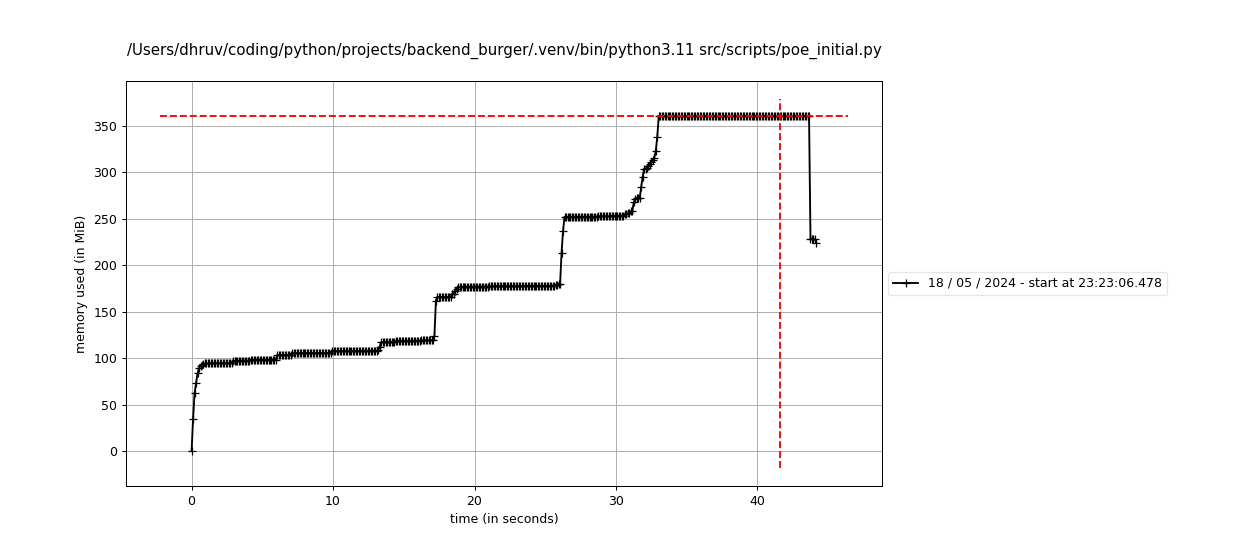
This can be verified by simply restricting the maximum length of the item_data array to 10,000, which would restrict the number of accessed item data records of the BaseType category, which has contains much more items. Making this change reduces the peak memory usage to ~285MB.
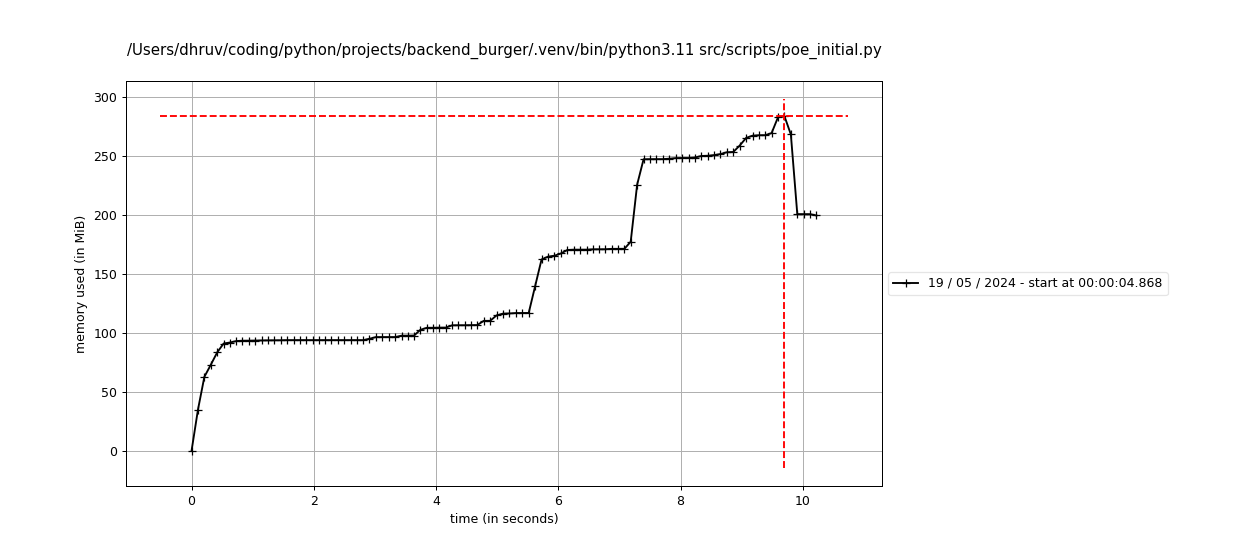
We can make one more improvement which will reduce both the memory usage and execution time, but requires a significant code refactor.
The Better Approach: Producer-Consumer Pattern
The mostly overhauled script using this approach is available here. We rewrote the main functions, moved API calls to their own functions, added more logging statements, handled errors and wrapped the async functions into async Tasks. These pass data using dedicated Queues and run until they get the termination signals using sentinel values.
Implementing Async Producer and Consumers means we now process information faster, by using different async tasks to concurrently get API data, parse that data, and save documents in bulk in the database.
This coordination allows us to reduce the time taken further to about 9 seconds, and all the tasks finish execution almost one after the other. This is an improvement of about 1.7 seconds over the bulk-insert implementation. We also witness a big drop in memory usage, with the peak memory usage being ~271MB, or an improvement of ~ 22.6% over the previous consumption of 350MB. These are fantastic results, in my opinion.
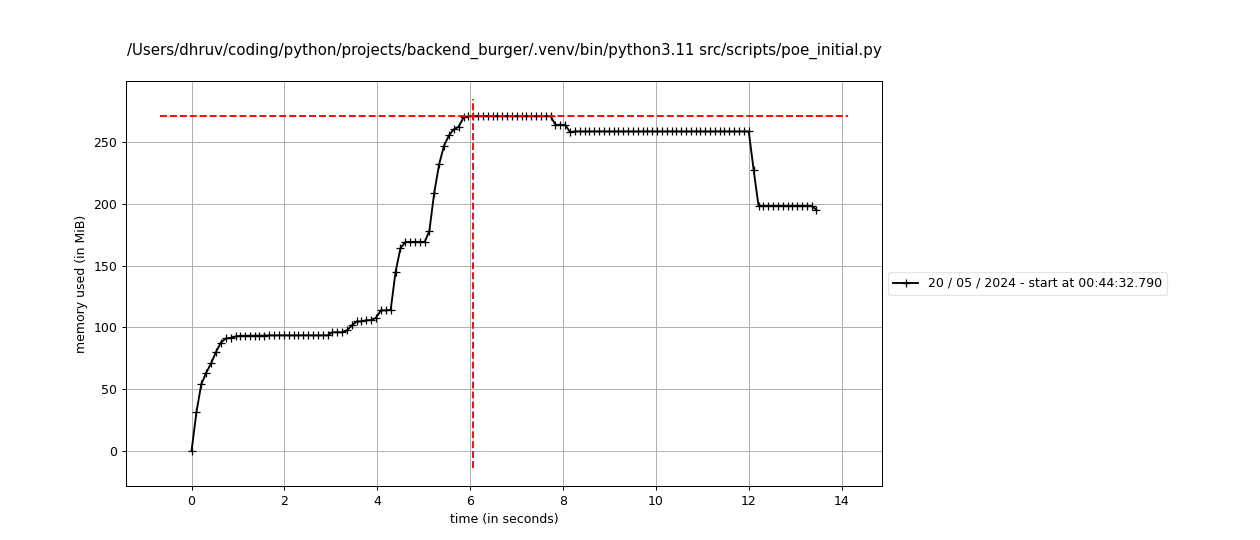
Conclusion
This was a journey where I got hands-on with some general performance improvements for database writes and also implemented the common but very effective Producer-Consumer design pattern. I am sure that there are things that I missed and certain aspects that can be handled better, I’ll be keeping an eye out for any improvements.
It was a great learning and experimental experience for me, and I hope that this made a good read for you. Please do not hesitate to email me if you wish to discuss anything. I will be adding comments functionality to the site soon.